Un (petit) coup de pouce pour interroger l’index
Pour être positionné sur un moteur de recherche, il faut bien évidemment que les pages de votre site soient indexées par le moteur de recherche en question. L’un des axes d’optimisation technique d’un site consiste à faire en sorte que ce dernier concentre son évaluation sur ce qui « mérite » d’être vu (d’un point de vue SEO) et non pas sur des pages périmées ou sans contenu digne de ce nom qui, outre de gaspiller les précieuses ressources que Google alloue à votre site, nuirait à la qualité globale de ce dernier au point d’entraîner une pénalité !
Nous ne débattrons pas ici sur les pages qu’il faut indexer ou pas, mais sur l’un des problèmes récurrents que l’on constate quand on effectue un audit : la surindexation dans Google. Les différences entre le nombre de pages que l’on peut extraire par un crawl et/ou que l’on pensait indexées, et le nombre de pages que Google prétend posséder effectivement dans son index sont en effet souvent surprenantes.
Aussi, disséquer l’index est une priorité majeure, et les techniques se comptent sur les doigts de la main (ok, j’arrête ma sémantique digitale sinon les algos ne vont pas comprendre le sujet traité !)
Combien d’url indexées par Google ?
Google search console (GSC) et la fonction « site: » de Google donnent globalement des résultats assez voisins. Si le premier outil ne donne pas directement la liste des pages indexées (on pourra avoir un aperçu par le biais des pages de destinations de l’outil « Analyse de la recherche » pour celles qui ont été affichées dans les Serps les 3 derniers mois, voire éventuellement via la liste des liens internes), la seconde fonction demeure la plus intéressante, à condition de segmenter et préciser sa recherche par le biais des autres fonctions que le moteur de recherche nous offre encore.
La fonction site:(www.)monsite.fr a en effet la particularité de nous annoncer un premier nombre, souvent important, mais au bout de quelques pages, ce dernier apparaît soudainement très bas ! Parmi les explications d’une telle dévaluation, citons notamment :
– Un nettoyage suite à une refonte : les urls disparues (404 / 410), redirigées (301), et/ou interdites au crawl par le robots.txt, sont en grande partie reléguées plus ou moins longtemps dans un index secondaire (c’est le cas de l’exemple de la figure 1, avec la refonte de notre site fin 2015). Notons que depuis plus d’un an, les urls redirigées ont la fâcheuse tendance à rester très longtemps dans l’index, y compris dans l’index primaire ! Les urls redirigées par une redirection temporaire 302 sont également vouées à cohabiter dans l’index en compagnie de l’url de destination.
– Google ne donne qu’un échantillon des urls du site : les urls non proposées peuvent être des pages dont le contenu est sensiblement égal aux autres ou (quasi) absent, ou encore des urls artificielles créées par du spam (voir notre exemple figure 2), ou encore des urls devenues orphelines au cours de l’histoire de site, c’est-à-dire qu’il n’y a plus de liens entre elles et les pages du site que vous avez pu relever via votre crawl. Au passage, attention à l’interprétation de votre crawl : certains « spiders » ne sont pas totalement au point quant à la reconnaissance de certains liens en javascript, voire de ceux présents dans certaines balises (cf: hreflang), alors que le Googlebot est parfaitement capable de les lire.
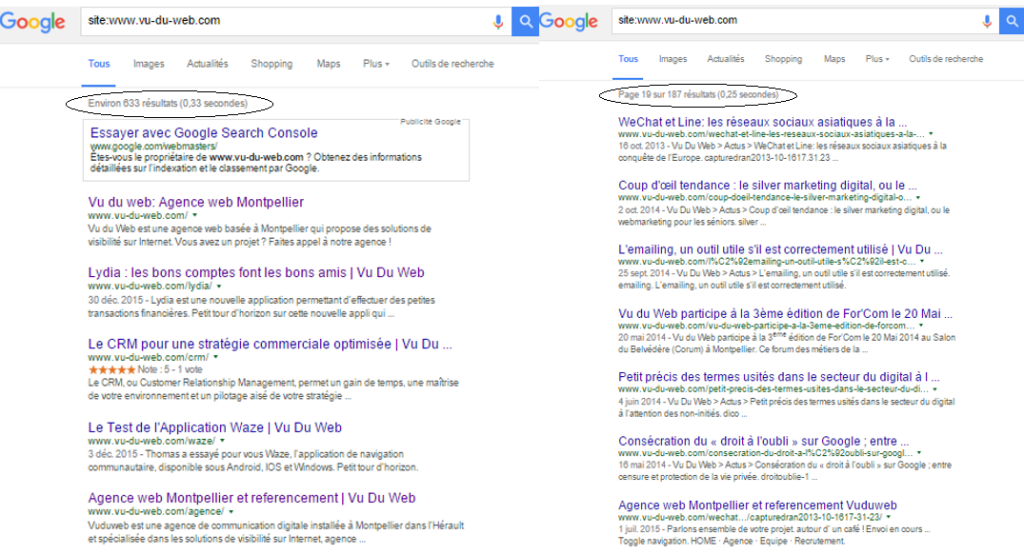
figure 1 : exemple de données contradictoires de l’indexation des pages de Vu du Web sur Google (suite à notre refonte).
Ainsi, l’opération consistant à relever un maximum d’urls de l’index s’avère très fastidieuse en fonction de l’importance du nombre d’urls effectivement indexées par Google. La stratégie globale consiste à tester tous les cas de figures qui génèrent ou peuvent générer des urls indésirables.
Segmenter pour mieux rechercher
Dans un premier temps, relevez toutes les urls que vous donne la fonction « site:» de Google. Je vous conseille pour cela d’utiliser un outil tel que Serpitude de Ranktank qui vous permettra d’exporter la liste des résultats dans un fichier csv. Relevez ensuite les différents cas de figure qui se présentent à vous : monsite/dossier-x/…, monsite/(…)/(…)¶m=xxxx, monsite/54543353.html monsite/author/, etc.
Dans un second temps, utilisez la fonction « inurl » pour filtrer les mots constituant les urls: « inurl: »cas-de-figure »» (eg site:monsite.fr inurl: »¶m= »), agrémentée d’un &filter=0 pour insérer les « pages similaires » pouvant être proposée dans un second temps quand vous atteignez la dernière page de résultats : le nombre d’urls pourra alors s’avérer beaucoup plus exhaustifs que précédemment. Chaque CMS ayant ses petites particularités quant à pouvoir créer des pages indésirables, l’expérience permet de pointer rapidement là où ça fait mal !
Vous pouvez éventuellement utiliser « intitle: » pour filtrer l’index à partir du contenu de la <title> si vous avez repéré des patrons particuliers concernant le contenu de cette balise. Testez également la fonction « filetype » qui vous permettra d’extraire les éventuels urls des pdf (filetype:pdf) et autres extensions prises en compte par google (php, js, xml, css …) qui peuvent, elles aussi, réserver quelques surprises pas piquées des vers (ah, les flopées de vieux pdf oubliés sur le serveur !).
Si il reste encore un nombre non négligeable d’urls indéterminées, listez également les urls des pages vues sur Google Analytics : de nouveaux patrons d’url peuvent être découverts. Si vous avez un compte sur un outil de type Majestic, listez également les pages de destination de vos backlinks pour les mêmes raisons. N’oubliez pas les résultats des autres moteurs de recherche et leurs outils pour les webmasters (Bing ou de Yandex) qui pourront peut-être mettre en lumière quelques types d’url que Google aura négligés. Enfin, le top est d’avoir accès à ce que le Googlebot a vraiment « vu », à savoir les logs serveurs, qui délivreront la liste exhaustive de toutes les urls uniques que Google aura testées sur votre nom de domaine.
Vérifier le spam
En plus de tout ce que vous pourrez extraire, pensez à inclure quelques termes « spammy » dans vos filtres, surtout si votre site est géré sur un CMS populaire, et d’autant plus si vous pensez avoir été pénalisé. Des recherches du type « inurl / intitle: »acheter » », « inurl/intitle: »viagra » pourraient délivrer leur lot de mauvaises surprises (cf figure 2). N’oubliez pas non plus, au passage, les « lorem ipsum » et autres « test », encore assez récurrents …
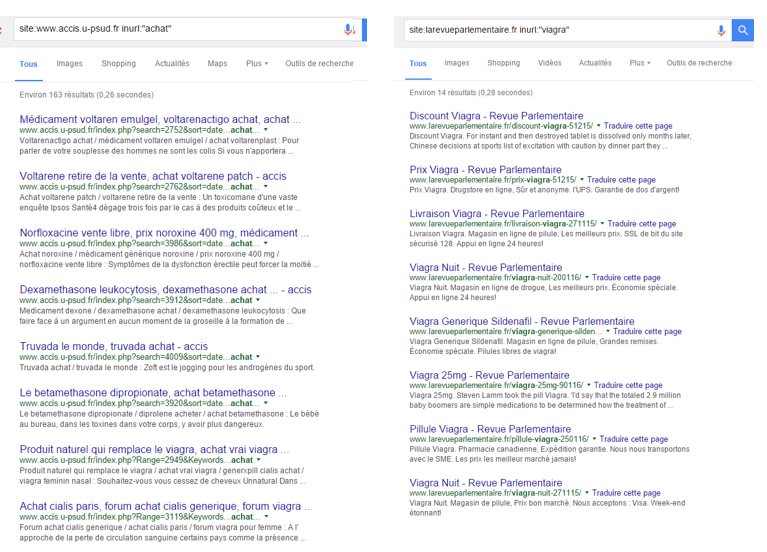
Figure 2: exemple de surindexation provoquée par le spam
La méthode ne garantit pas une extraction à 100%, mais vous aurez sans doute résolu une partie du mystère relatif à la surindexation de votre site internet par fusion de vos différentes listes d’urls. Elle permet au passage de relever des problèmes techniques qui préviendront, dans le futur, une nouvelle surindexation d’urls par duplication ou génération de pages sans contenu. Ainsi, vous pourrez entreprendre votre campagne de désindexation / prévention en vous concentrant sur celles qui répondent en 200, mais sans oublier les 404 bloquées par le fichier robots.txt (nous reviendrons ultérieurement sur le sujet).
Si avec toutes ces techniques, il vous reste encore des interrogations, n’hésitez pas à nous contacter, nous prendrons grandement plaisir à vous répondre.
Passionné par le marketing 360° et le growth hacking, Laurent Thomas pilote la stratégie marketing et les innovations produits au sein de l’agence. En veille constante, c'est désormais l'intelligence artificielle (IA), qu'il explore avec autant de fascination que d'appréhension, pour permettre aux clients de gagner en efficacité et en performance.